Why AI Projects Stall Between Prototype and Production
The demo worked. Here is what actually blocks teams from getting it into production.

Puneet Anand
Getting a prototype working is not the hard part anymore.
A team can wire up a workflow, call a model, get a decent answer on a sample input, and show something promising in a demo. That part is real progress. But it is also where a lot of AI projects start to fool people. The gap between “it works” and “we can put this in production” is still large, and most organizations are stuck somewhere inside it. McKinsey’s 2025 global survey says nearly nine in ten respondents report regular AI use in at least one business function, but only about one-third say their companies have begun to scale AI programs. McKinsey also says the move from pilots to scaled impact is still a work in progress at most organizations. (McKinsey & Company)
That matches what we keep hearing in customer conversations. Teams are not usually blocked because the model is bad. They are blocked because they cannot prove that what they built actually works reliably: what is failing in production, whether the right people have reviewed it, and whether fixes held without breaking something else. In one recent conversation, an engineer said the goal was to get enough confidence to tell leadership, “this solution is working,” and only then push it to production. In the same discussion, that engineer said the real wish was to create the specific scenarios needed to test every path through the workflow.
What changes after the demo
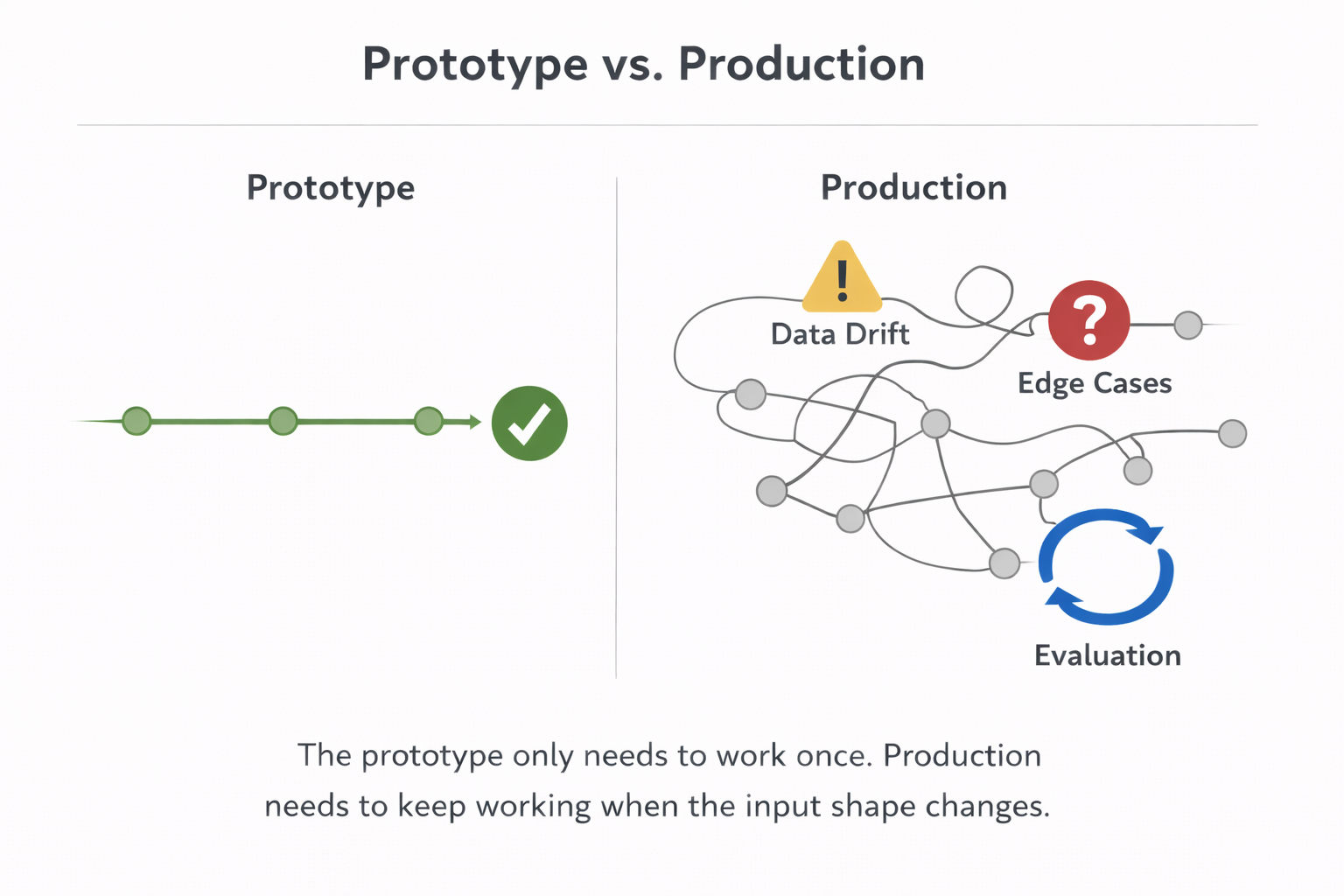
Early on, a prototype only has to show that the idea is possible.
Production has a different job. It has to keep working when the data is messy, when inputs branch in ways nobody wrote down, when edge cases show up, and when the team has to explain why they trust the output enough to attach it to a real business process.
One team we spoke with had already built the workflow logic and was moving toward automation, but described the real problem as “endless possibilities.” Their point was simple. The manual process had accumulated lots of exceptions over time, and once you try to automate it, you need test sets that cover those branches instead of just a clean happy path. Their words were that they needed to “cover everything” and test “every path” that could be traversed.
Another team described a similar problem, but from the evaluation side. The issue was not getting the evaluator to work. The issue was trusting it beyond the prototype. They kept coming back to the same point: until the test and evaluation data covered a broader range of realistic variation, the early results were not enough to create real confidence.
Those are two different projects. The underlying problem is the same.
The first blocker is confidence
This is usually the real gate.
Engineers know a prototype is not production-ready just because it ran correctly ten times in a row. Managers know it too, even if they do not always say it that way. What they want is confidence that the thing will keep behaving when it hits the real shape of the work.
That is why one of the strongest patterns in our calls has nothing to do with model architecture. It is about what someone can defend in front of their own leadership. In one conversation, the engineer said the outcome they wanted was confidence for the team, confidence that the graph or workflow really worked, and confidence to move to the next version.
Public research lines up with that. McKinsey says most organizations are still not embedding AI deeply enough into workflows and processes to realize material enterprise-level benefits, and that redesigning workflows is one of the strongest factors associated with meaningful impact. It also says defined processes for deciding when model outputs need human validation are among the practices that distinguish high performers. (McKinsey & Company)
That matters because confidence is not a feeling. It comes from evidence: knowing what is actually failing in production, having the right people confirm whether the output was correct, and being able to show that a fix held without breaking something else. Most teams we spoke with did not yet have a reliable way to do any of those three things.
The second blocker is finding what is actually wrong
The way most teams found out something was wrong was through a user complaint, a thumbs down, or someone manually spot-checking traces. By the time the failure surfaced, it had already reached real users.
What made this harder was that most failures do not announce themselves. An agent can finish a task and return a response that reads like a valid answer but is wrong for the domain, incomplete in a way only someone with context would catch, or stated with confidence not supported by the retrieved documents. Latency metrics and error rates catch none of that. Customers told us their dashboards showed everything green right up until a domain expert actually looked at the traces.
We also heard about something adjacent to failures: traces that were not wrong but were worth paying attention to for other reasons. Topics that came up more than expected, edge cases the team had not anticipated, outputs that were surprisingly good and worth understanding, patterns in how users were phrasing requests. We started thinking of these as signals. Finding them requires the same kind of active search as finding failures, but for a different reason: not to fix something, but to understand how the system is actually being used and what it is revealing about user needs.
The third blocker is understanding why it failed
Finding a failure is one problem. Understanding where it came from is a different one, and often slower.
In most AI workflows, a bad output could have come from almost anywhere: the prompt, the retrieval step, the chunks that got selected, a tool call that returned the wrong thing, a reasoning step, model behavior on that particular input type, or something in the workflow logic upstream. The output itself usually tells you nothing about which one it was. Customers told us that even experienced engineers were spending significant time digging through trace logs and still not certain of the root cause by the end.
Agentic systems made this worse. When a multi-step agent produces a bad result, the actual failure is often several steps back, buried in a decision that everything else built on. You cannot tell by reading the final output where things went wrong, which meant teams were either guessing or investigating one trace at a time.
The fourth blocker is getting the right people to review it
Even when a team has found a failure and has some idea of where it came from, deciding whether the output was actually wrong often requires someone who knows the domain. An engineer can tell you the retrieval returned three documents. A compliance officer can tell you whether the answer those documents produced would create a legal problem. Those are different judgments, and both matter.
Customers told us that getting domain experts into the review process was consistently harder than it looked. There was no standard way to share a trace with context, ask a specific question, and get an answer that engineering could act on. Reviews happened over Slack or in spreadsheets, the feedback was often too vague to translate into a fix, and rubrics either did not exist or were inconsistent between reviewers. We heard from multiple teams that expert review felt more like asking a favor than running a process.
Scale made it worse. Domain experts are expensive and busy, and most teams were asking them to review things ad hoc rather than through a system that gave them context, focused their attention on a specific question, and recorded their judgment in a reusable way.
The fifth blocker is trusting your evaluations
After a team finds a failure, understands the root cause, gets expert feedback, and makes a change, there is still the question of whether the change actually worked and whether it broke anything else.
LLM judges are the usual answer for scaling evaluation. Customers told us they helped, but the judge itself was often the weak link. A judge built on a narrow set of examples, or one not calibrated against what actual domain reviewers considered correct, would score outputs in ways that did not match what a real expert would say. We heard from one team whose judge was consistently approving outputs their compliance team would have flagged.
The regression problem was separate. Customers told us that a fix to one failure type would sometimes quietly break behavior on different inputs, and their test suites would not catch it because those inputs were not in the suite yet. That was one of the main reasons optimizations felt risky: not because the team doubted the specific fix, but because they had no reliable way to check whether it had created a problem somewhere else.
The sixth blocker is the process itself
Every team we spoke with was doing some version of the right things: reviewing outputs, updating prompts, running evals. But none of it was connected in a way that let one step feed into the next, and none of it built up into anything the next project could start from.
Customers told us that a reviewer would catch something and a fix would get made, but the lesson behind that fix would not make it into the eval suite or get documented anywhere the next team could find it. The improvement happened once and then stopped. We kept seeing the same pattern across different companies: work that should have accumulated was being repeated instead, because there was no shared record of what had been learned or why a decision had been made.
The teams that shipped were not always doing more work. They had a process where the review led somewhere: a regression test, a rubric update, something the next sprint could actually build on.
What teams that get through this do differently
The teams we saw get to production shared some patterns. They were looking for failures regularly rather than waiting for something to surface through a user complaint or a manual spot check, and customers told us that teams still waiting on production approval were mostly in the second category.
They also had a real system for getting the right people to look at the right things. Not Slack messages or one-off requests, but queues where reviewers got consistent context and knew exactly what they were being asked to judge. The feedback that came back was something engineering could act on directly.
What we found mattered most was what happened to that feedback afterward. Most teams we spoke with had done reviews. The ones still waiting for production approval had done reviews too. The difference was that in the teams that shipped, reviewed examples turned into regression tests, rubrics got updated as new problems showed up, and the next project started with more than the previous one had.
Where DataFramer fits
Customers told us the same thing in different ways: they did not know what was actually breaking until users found it, and when they did find something, there was no clean way to get the right person to look at it or carry the lesson forward.
DataFramer connects to your production traces and surfaces failures that do not show up in standard metrics. Outputs that are wrong, incomplete, or off in ways that only someone familiar with the domain would catch. You can see roughly where in the workflow it broke and route those traces to people who can actually judge whether the output was correct. They review with shared context and rubrics so the feedback is consistent and usable, rather than scattered across Slack threads and spreadsheets.
What customers kept telling us was that reviews happened and fixes got made, but nothing stuck. The next project started from scratch. The failure patterns, the expert judgment, the regression tests built from reviewed examples all accumulate in DataFramer and carry into the next rollout.
The short version
AI projects rarely slow down because the prototype was bad. They stall because the team cannot confidently answer a few things: do we know what is actually breaking in production, have we gotten the right people to look at it, and have we proven the fix worked before we ship it.
McKinsey found that nearly nine in ten companies are using AI in at least one function but only about a third have managed to scale it. (McKinsey & Company) That gap mostly comes down to the quality process: finding failures, reviewing them, fixing them, and carrying the lessons forward is still manual and fragmented at most organizations.
The teams that close that gap are not necessarily doing more work. They just have a process where the reviews lead somewhere, and the next project starts with more than the last one had.
Get started
Ready to build better AI with better data?
The real bottleneck in AI isn't intelligence. It's the data you can't generate, can't share, or can't trust.