
LLM and Agentic Evaluation: Why Eval Dataset Coverage Matters More Than Size
The issue is rarely too few eval rows. It is eval data that misses the real spread of cases, slices, and failure modes.

Puneet Anand
A lot of teams assume their eval problem is scale.
They think the answer is to collect a lot more rows, label a lot more examples, and push the benchmark size up until the results feel real.
That is usually not the real issue.
In several customer conversations, the pattern was different. Teams could already get an evaluator or grading loop running. What they did not trust was how well it would hold up once they moved beyond the small set of examples that shaped the first version. The thing they kept coming back to was coverage. Their test and eval data did not reflect enough real variation, so the early scores did not create real confidence.
That lines up with public guidance from major LLM evaluation frameworks, including those published by OpenAI and Google. OpenAI says evals should reflect model behavior in real-world distributions and warns against eval datasets that do not reproduce production traffic patterns. It also says human feedback should be used to calibrate automated scoring. Google Cloud says test data should be representative of the data as a whole and that teams should check model quality on important slices so fine-grained failures do not get hidden by a global metric.
A small eval set could actually be enough.
Why teams get this wrong
Early on, the LLM or agentic workflow usually looks better than it really is.
The first eval set is often built from easy examples, recent examples, or whatever the team already has on hand. That is enough to get a loop going, but not enough to tell you where the system will actually break.
In one customer conversation about internal evaluation work, the team said the quality of their evaluation process was shaped more by dataset diversity than by raw dataset size. They were working with relatively small eval sets and still felt that a few hundred examples could be enough if those examples were actually high quality and varied. Their problem was not “we only have hundreds.” Their problem was “these hundreds do not cover enough of what matters.”
That is a very normal place to land.
If the evaluation dataset is repetitive, the LLM can look stable without actually being robust. The score goes up, but what improved was fit to the benchmark, not fit to the real world.
Google’s Rules of ML makes the broader engineering point. Most of the hard problems teams run into are engineering problems, not pure algorithm problems, and a lot of gains come from getting the data and pipeline right.
The same pattern appears in fine-tuning datasets. A narrow fine-tuning dataset teaches the LLM the patterns it already handles well. It does not expand the range of inputs the model learns to handle correctly, and teams typically discover that gap after deployment rather than before it.
What “narrow” actually means
“Narrow” does not just mean small.
It means the dataset is missing the spread of cases you care about.
That can show up in a few ways:
- the examples all come from one common path
- the examples are too clean compared with real usage - the Happy paths
- the same patterns repeat with slightly different wording
- the dataset misses the awkward edge cases that cause disagreement
- the benchmark reflects the seed data more than the live distribution
RAG pipelines are a concrete example of where this shows up. Teams building retrieval-augmented systems typically assemble their evaluation dataset from the clearest, best-formed questions in their documentation. Those are the easy cases where retrieval works cleanly. Real RAG failures happen on ambiguous queries, multi-hop questions, and inputs where the retrieved context is partially relevant but not quite sufficient to answer correctly. A narrow RAG evaluation dataset built from clean examples scores well on those examples and misses most of the failure modes that matter in production. The RAG evaluation problem is not usually a data volume problem. It is a coverage problem.
Agentic workflows have the same issue in a different form. An agent can complete every step in a task and return a clean-looking output while having skipped a required verification, dropped context from earlier in the conversation, or missed a business-specific constraint that nobody thought to test for. Customers told us these are the hardest failures to catch because they look like successes by every automated measure. The only thing that surfaces them is someone who knows the domain actually reading the output.
OpenAI’s eval guide is very direct here. It recommends task-specific evals that reflect real-world distributions and calls it an anti-pattern to create eval datasets that do not faithfully reproduce production traffic patterns.
Anthropic says much the same thing from an agent-evals angle. It recommends turning real manual checks, user-reported failures, and actual product requirements into test cases, and says frameworks are only as good as the eval tasks you run through them. Their advice is to invest energy in high-quality test cases and graders, not just the framework around them.
That is why a narrow eval set is dangerous. It gives you repetition without real breadth.
Why small but broad often beats large but repetitive
This is the part many teams do not want to hear because “collect more data” sounds safer than “think harder about coverage.”
But in practice, a smaller dataset with good spread is often more useful than a larger one full of near-duplicates.
You see this in ML guidance too. Google Cloud recommends keeping a separate holdout set, making sure train, validation, and test splits are representative, and testing on important slices to avoid hiding fine-grained problems behind one global number.
You see it in LLM eval guidance as well. OpenAI recommends eval-driven development, logging everything so you can mine real traces for good eval cases, and maintaining agreement between LLM-as-a-judge scoring and human judgment.
And you see it in the customer conversations. The teams that sounded closest to a workable process were not asking for giant abstract corpora. They were asking for broader and more realistic variation around the cases they already knew mattered. They wanted to expand a seed evaluation dataset into something that covered more of the actual space they cared about.
That is a very different job than just making the dataset bigger.
One downstream effect of a narrow eval set that teams often do not notice until late is what it does to an LLM judge. If a judge is calibrated against examples that are all easy or concentrated in one slice of the problem, it learns to approve that slice with confidence. We found that customers who had built judges on top of narrow eval sets were getting high scores on outputs a domain expert would have flagged. The judge had not failed. It had done exactly what it was calibrated to do. Broadening the eval coverage is often what exposes that the judge and the benchmark were both tuned for the wrong thing.
What good eval coverage looks like
For technical teams, this usually comes down to a few practical questions:
Are we covering the major slices of behavior we care about?
Are we including edge cases that have already caused bad outputs or human disagreement?
Are we checking the cases that matter to the business, not just the cases that are easy to label?
Does the dataset still look like live traffic, or has it drifted into benchmark theater?
The question is “how much of the real problem space do these rows actually cover?” Ground truth data is only as useful as the range of cases it represents.
What teams should do differently
A better approach usually looks like this:
Start with the seed set you trust. In practice this is your golden dataset: the examples you are confident enough to build from.
Then ask where it is thin.
Look for repeated patterns, missing slices, common failure cases, and the places where human reviewers tend to disagree or slow down. Add examples that expand the range, not just the volume.
This might be best done in partnership with Product Managers of Business Experts (Underwriters, Healthcare/Clinical experts, Legal experts, etc.), depending on your the nature of business / industry you work in.
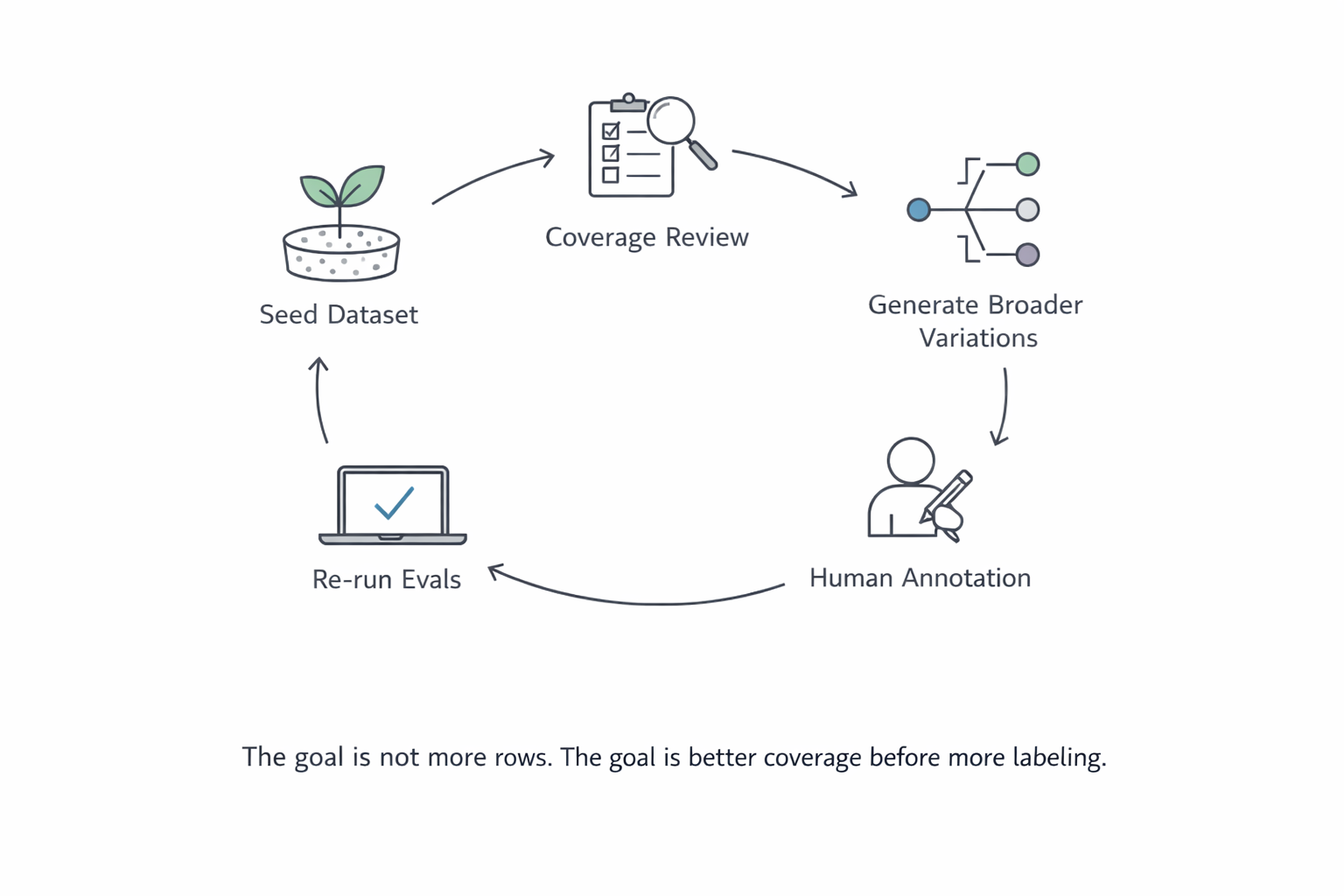
In one customer conversation, the team described the desired workflow very clearly. They wanted to start with an existing seed dataset, broaden the diversity of the input data, then have humans annotate the new examples before feeding them back into the evaluation loop. The point was not to replace human judgment. The point was to make the underlying eval set more useful before spending labeling time on it.
That is a sensible pattern:
- start from real seed data
- expand the variation intentionally
- complete dataset annotation on what matters
- rerun the eval
- look at where trust improves and where it still does not
The best source of new eval cases is usually already sitting in your production traces. Customers told us that teams who made the most progress on coverage were not building evals in isolation from what was happening in production. They were pulling real failures, edge cases that surfaced through user feedback, and outputs that caused disagreement during review, and feeding those directly into the eval set. A failure that reached a real user and got flagged is already a well-grounded test case. It does not need to be invented. It needs to be captured and added before the next version ships.
The annotation step in that process is where most teams slow down. Getting domain experts to review the new examples and flag what is still missing is hard to structure. Experts are busy, their feedback tends to be inconsistent, and without agreed rubrics one reviewer’s judgment does not transfer to the next. When reviewers disagree on the same example, that is usually the rubric being ambiguous rather than the reviewers being wrong, and it is worth fixing before more gets built on top of it. Customers told us that the teams who made real progress on coverage had treated expert review as a workflow rather than an ad hoc ask: specific examples routed to the right people with a clear question to answer and a way to record the judgment consistently so it could inform the next round.
It is also a much better use of time than labeling large amounts of repetitive data.
What to look for in a solution
If your team is evaluating tools in this area, the key question is not “can it generate more data?”
The real question is whether it can help you widen the dataset in the right way.
A useful solution should help you:
- start from examples you already trust
- preserve the structure that matters
- automatically generate broader variation, grounded in your real data, without drifting into nonsense
- make missing slices and recurring failure patterns visible
- support a human-in-the-loop review workflow, with a shared rubric so expert judgment stays consistent and reusable
- carry those human verdicts as ground truth, so an automated judge can be calibrated against them instead of trusted blind
That is the job. Not generic generation. Not volume for its own sake.
That is the measure of any tool in this space. Not whether it makes the dataset larger, but whether it helps the team turn a narrow evaluation dataset into a broader one that actually tests what matters.
The short version
If your eval results look fragile, the first thing to question is not the row count, but question the coverage.
A small eval set can still be useful if it reflects the real spread of cases, the important slices, and the kinds of failures the team actually needs to catch. A larger eval set can still be weak if it mostly repeats the same pattern over and over.
That is the common thread from both customer conversations and public guidance. Teams need evals that reflect real distributions, calibrate well against human judgment, and stay broad enough to expose failure modes instead of hiding them.
So yes, small eval datasets CAN be enough. They just cannot be narrow.
How DataFramer Helps
DataFramer is built around this exact loop. It surfaces the recurring failure patterns hiding in your production traces, routes the ones that matter to experts who grade them against a shared rubric, and turns those verdicts into ground truth. From there it calibrates a judge against your reviewers and fills the thin slices with synthetic examples grounded in your own data, so coverage widens without drifting from what real usage looks like.
Announcing DataFramer: AI Workflow Intelligence for Accurate, High-Value AI Workflows
Three roles, one question: is our AI actually working? DataFramer is the AI Workflow Intelligence Platform built to answer it.
Puneet Anand Why AI Projects Stall Between Prototype and Production
The demo worked. Here is what actually blocks teams from getting it into production.
Puneet Anand Your AI Is Confidently Wrong, and That Is a Business Problem
The dangerous AI mistakes aren't the obvious ones. They're fluent, confident, and wrong, and the business pays before engineering ever knows.
Puneet Anand Get started
Ready to build better AI with better data?
The real bottleneck in AI isn't intelligence. It's the data you can't generate, can't share, or can't trust.