An Overview of Retrieval-Augmented Generation (RAG) and Its Different Components
RAG components, retrieval strategies, and how to build systems that ground LLM outputs in real data.
DataFramer Team
Large language models are powerful but limited by what they were trained on. Their training data has a cutoff date, and they have no access to your organization’s internal documents, your product knowledge base, or anything domain-specific that wasn’t in their training set. Retrieval-Augmented Generation (RAG) addresses this by connecting the LLM to an external knowledge base at query time.
What is RAG?
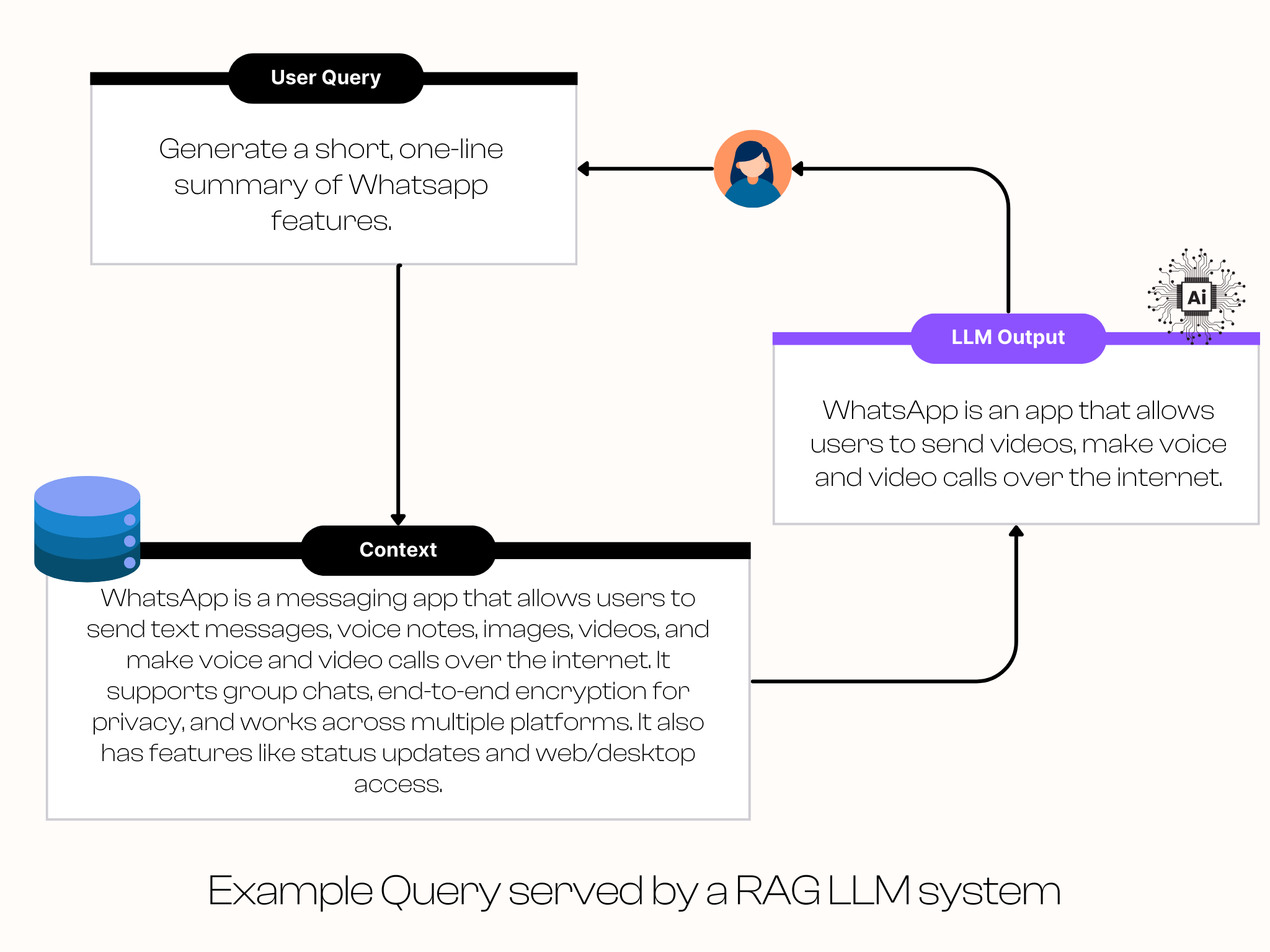
RAG is a technique that enhances LLM outputs by supplementing the model’s input with relevant information retrieved from external data sources. Instead of relying solely on knowledge encoded in the model’s parameters, a RAG system fetches relevant context from sources like internal documents, database tables, or company tickets, and passes that context to the LLM along with the user’s query.
The result is responses that are grounded in your actual data rather than in what the model learned during training.
How RAG works
The process follows four main steps:
- Documents are processed and indexed into a vector database as dense vector embeddings that capture semantic meaning.
- A user submits a query in natural language.
- The system searches the vector database for documents that are semantically similar to the query.
- The retrieved documents are combined with the user’s query and passed to the LLM as context for generating a response.
The choice of vector database has a real impact on retrieval quality and scalability. Our comparison of popular options covers the key tradeoffs.
Why use RAG?
Three practical benefits:
- Reduces hallucinations. Grounding responses in retrieved information means the model has actual context to draw from rather than guessing.
- Stays current. Static training data becomes outdated. A RAG system that pulls from a live knowledge base gives accurate answers even as information changes.
- Requires less fine-tuning. You can update your knowledge base without retraining the model.
Key components
A RAG system has three main components: indexing, retrieval, and generation.
Indexing
Indexing is where you prepare your knowledge base for efficient retrieval. Raw data, structured or unstructured, is converted into vector embeddings and stored in a vector database.
Embedding models do the work of converting text into dense vector representations that capture semantic meaning. They’re used both when indexing documents and when encoding incoming queries. OpenAI’s text-embedding-3-small and NVIDIA’s NV-Embed-v2 are two commonly used options. The choice of embedding model matters: generic models can underperform on specialized domains.
The quality of your indexing directly affects retrieval quality. Chunk size, document processing approach (especially for formats like PDF), and embedding model all have downstream effects on how well the system retrieves relevant context.
Retrieval
When a user submits a query, the system encodes it as a vector and searches the database for documents with similar embeddings. Similarity metrics like cosine similarity or Euclidean distance determine what gets returned.
The goal of retrieval is to find documents that are genuinely relevant to answering the query, not just superficially similar. Getting this right often requires tuning chunk strategies, reranking, and retrieval parameters based on how the system actually performs.
Consolidation
Before passing retrieved documents to the LLM, it’s worth filtering and prioritizing them. Token limits mean you can’t pass everything that was retrieved. This step involves removing irrelevant or redundant chunks, reranking by relevance, and sometimes summarizing to reduce token count while preserving the most important context.
The distinction between retrieval and consolidation: retrieval finds candidate chunks that might answer the query; consolidation narrows them to a precise set that the LLM can use effectively.
Generation
The LLM receives the retrieved context alongside the user’s query and generates a response informed by both. If the retrieval step worked well, the model has the information it needs to give a grounded, accurate answer. If retrieval failed, the model is left to fill gaps with its own (potentially hallucinated) knowledge.
Types of RAG systems
Text-based RAG uses keyword or semantic search to retrieve relevant documents. This is the most common approach and works well for most text-heavy knowledge bases.
Graph-based RAG builds a knowledge graph representing entities and relationships, enabling more complex reasoning over interconnected information. It’s more computationally intensive but handles queries that require understanding relationships between concepts.
Hybrid RAG combines both. It’s well-suited to use cases where you need both broad semantic recall and precise structured reasoning.
The right choice depends on your data: how interconnected it is, how much structure it has, and what kinds of queries you expect users to ask.
Evaluating your RAG system in production
Building the pipeline is the easier half. Knowing whether it actually works in production is harder, and most teams underinvest in it.
The silent failure problem. RAG systems often fail without any visible signal. The response looks complete and confident. The model retrieved a chunk that was topically adjacent to the question but lacked the specific fact needed, filled the gap with something plausible, and returned an answer that passes a quick read. These failures accumulate quietly until they surface as complaints, compliance issues, or eroded trust.
Four metrics worth tracking. The RAGAS framework (Es et al., 2023) breaks RAG evaluation into four dimensions:
- Context precision: what fraction of retrieved chunks were actually useful for answering the query?
- Context recall: did the system retrieve everything needed for a complete answer?
- Answer faithfulness: does the response stick to what was in the retrieved context, or does it add things not found there?
- Answer relevance: does the response address what was actually asked?
Each of these can fail independently. A system with high context recall but low faithfulness is surfacing the right documents but the LLM is ignoring them. A system with high faithfulness but low context recall is being honest about incomplete information. Treating RAG quality as a single score hides which layer broke.
Production queries are not test queries. Golden datasets test clean, well-formed queries that roughly match your knowledge base. Real users ask vaguely, use different terminology, and hit edge cases your test set never anticipated. A RAG system that scores well on a golden dataset can still fail regularly once real users interact with it. Research from Stanford found that LLMs lose track of relevant information when it appears in the middle of a long context window, not just at the beginning or end (Liu et al., 2023), meaning a retriever that correctly surfaces the right document can still produce wrong answers depending on where that document ends up after consolidation.
Root cause matters for fixing things. When a wrong answer comes out of a RAG system, there are several distinct places it could have gone wrong: the document wasn’t in the knowledge base, the retriever didn’t surface it, consolidation filtered it out, or the LLM generated outside the context. These require different fixes. Improving chunking doesn’t help if the problem is the LLM ignoring what was retrieved. Tracking failure root causes over time (retrieval failures vs. generation failures vs. knowledge gaps) is what makes RAG improvements systematic rather than guesswork.
The best evaluation datasets come from real production queries that exposed real failures, not synthetic examples written in advance. When a production failure gets diagnosed, that trace becomes a test case. Over time, production-derived test cases give you coverage of actual failure modes rather than imagined ones.
Conclusion
RAG is the most practical way to ground LLM responses in domain-specific, current information without constant retraining. The key insight is that the quality of the full pipeline matters: a strong LLM with a weak retriever or a poorly maintained knowledge base will still hallucinate frequently. Investing in data quality, indexing, and retrieval tuning compounds over time, and so does investing in the evaluation infrastructure that tells you where the pipeline is actually breaking.
The next article in this series covers the most common RAG failure modes and how to address them.
A Quick Comparison of Vector Databases for RAG Systems
ApertureDB, Pinecone, Weaviate, and Milvus compared on features, performance, and RAG use cases.
 Preetam Joshi
Preetam Joshi A Practical Guide to Agentic LLM Frameworks
A practical overview of agentic LLM frameworks: reasoning, planning, tool use, and the real challenges of running them in production.
Puneet Anand How to Fix Hallucinations in RAG LLM Apps
Concrete techniques for diagnosing and reducing hallucinations in RAG-based LLM applications.
Puneet Anand Get started
Ready to build better AI with better data?
The real bottleneck in AI isn't intelligence. It's the data you can't generate, can't share, or can't trust.