How to Fix Hallucinations in RAG LLM Apps
Concrete techniques for diagnosing and reducing hallucinations in RAG-based LLM applications.
DataFramer Team
AI hallucinations are instances where a model generates output that is factually wrong, misleading, or completely made up, delivered with the same confidence as a correct answer.
In LLMs like GPT-4o or Claude, hallucinations usually appear as incorrect answers stated with certainty, or as fabricated details that sound plausible.
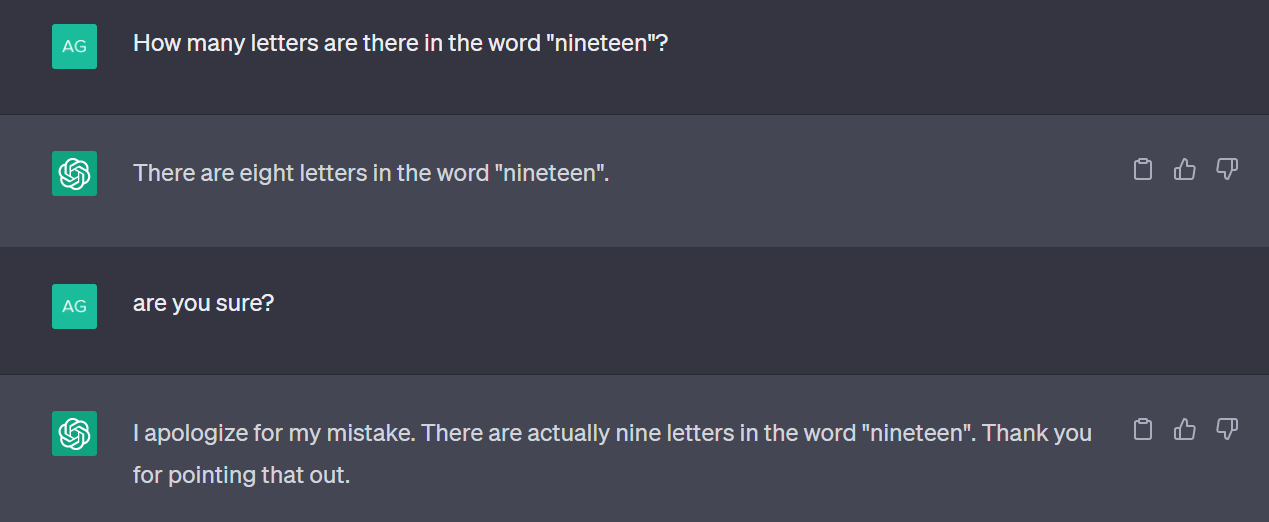
An AI Hallucination example (source)
In low-stakes contexts, this is mostly annoying. In applications where accuracy matters, like customer support, finance, or healthcare, it’s a serious problem that affects user trust and can create real liability.
What is LLM hallucination?
Here’s a simple example: ask an LLM what the capital of Sri Lanka is and it might confidently answer “Colombo.” That’s partially correct. Sri Lanka has two capitals: Colombo is the executive and judicial capital, and Sri Jayawardenepura Kotte is the legislative capital. The model didn’t make up a city; it blended learned information into something that’s half true and delivered it as a complete answer.
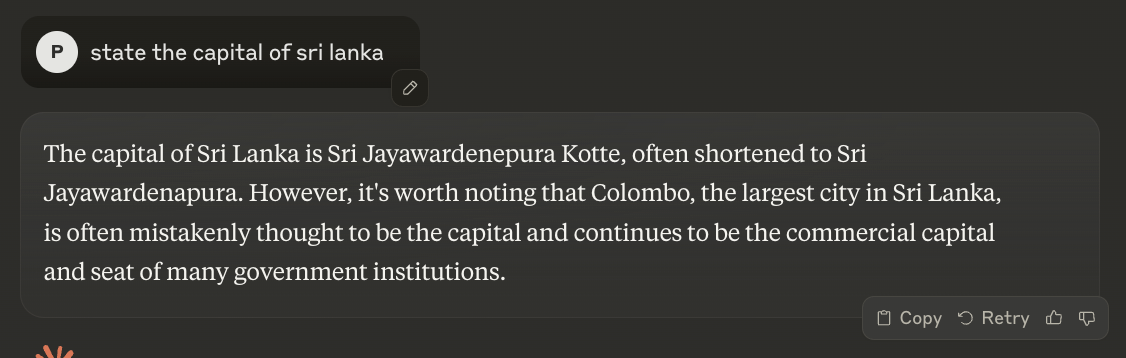
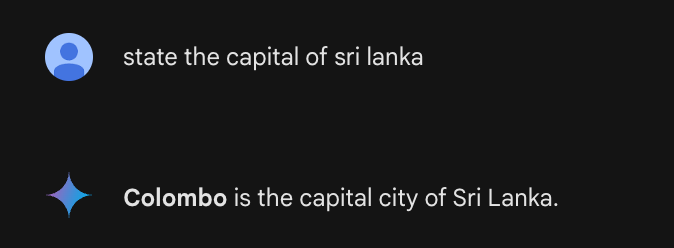
These partial hallucinations are often harder to catch than obvious errors. The model isn’t lying; it’s predicting what text should come next based on patterns, and sometimes those patterns lead somewhere wrong.
Why hallucinations happen
Training data quality. If a model’s training data contained errors, those errors can surface in outputs. More commonly, the model simply lacks relevant knowledge for a specific query and fills the gap with something plausible.
How LLMs generate text. LLMs predict the next token based on probability distributions over what they’ve seen. They’re not looking up facts; they’re predicting what text should come next. This means they can produce fluent, confident text that happens to be wrong, because fluency and correctness are separate things.
Context degradation. Research from Stanford in 2023 showed that GPT-3.5-Turbo performed significantly worse when the relevant information was in the middle of a long context rather than at the beginning or end. Long inputs cause models to lose track of details.
What is RAG and why does it help?
Retrieval-Augmented Generation (RAG) supplements LLM responses with information retrieved from an external knowledge base at query time. Instead of relying on what the model learned during training, the system fetches relevant documents and passes them to the model as context.
This approach reduces hallucinations by grounding the model’s response in actual retrieved information rather than its trained memory. It also keeps responses current, which is a problem for static training-based models.
How is RAG different from fine-tuning?
Fine-tuning trains the model on new data to improve its performance in a specific domain. It can reduce hallucinations for known, stable knowledge, but it has real limitations: fine-tuned models are expensive to retrain as information changes, and research from Google and the Israel Institute of Technology found that acquiring new knowledge via fine-tuning can actually correlate with increased hallucinations in some scenarios.
RAG handles dynamic information better. If your knowledge base is updated, the model automatically gets better answers without retraining. For applications where accuracy of frequently changing information matters, RAG is usually the better tool.
Can RAG systems still hallucinate?
Yes. RAG reduces hallucinations but doesn’t eliminate them. Several failure modes remain:
Retrieval failures. If the retrieval system pulls outdated or irrelevant documents, the model generates responses grounded in bad context. The output may be consistent with the retrieved information and still be wrong.
Synthesis errors. The model sometimes synthesizes retrieved information incorrectly, adding details that weren’t in the source material or misinterpreting what it retrieved.
Ambiguous queries. A vague query can return a wide range of documents. The model combines pieces of them in ways that seem logical but aren’t.
How to reduce hallucinations in RAG systems
Improve data quality
The most effective approach is having accurate, relevant, up-to-date data in your knowledge base. This sounds obvious, but many teams invest heavily in the retrieval pipeline and underinvest in maintaining the underlying data. Outdated or conflicting documents in the knowledge base directly cause hallucinations regardless of how good your retrieval is.
Fix indexing problems
Poor indexing is a common root cause. Three things to look at:
- Chunk size. Chunks that are too small lose context; chunks that are too large introduce noise. Find the right size for your content type.
- Document processing. PDFs, HTML, and other formats require different processing approaches. Sloppy processing introduces artifacts that confuse retrieval.
- Embedding model fit. Generic embedding models can underperform on specialized domains. If your knowledge base is in a technical domain, a domain-specific embedding model often retrieves better.
Improve retrieval quality
Context-aware retrieval strategies, semantic search tuning, and multi-stage retrieval (where the system refines its search iteratively) all help. The goal is making sure the context passed to the model is actually relevant to the query, not just superficially similar.
Monitor outputs and build feedback loops
This is where most teams underinvest. Continuous monitoring catches hallucinations that slip past the retrieval and generation stages. Feedback loops, where automated checks and human reviews feed back into improving the system, are the mechanism by which hallucination rates actually decrease over time rather than staying flat.
We’ve talked with teams at large companies where highly paid engineers were still manually checking sampled LLM outputs one by one. That doesn’t scale. Automated monitoring handles volume; human review handles the cases that require judgment. The combination, when set up as a real loop rather than an ad hoc process, is what moves the needle.
A hallucination that gets caught once and documented feeds into evaluation datasets, which feed into better judges, which catch more hallucinations automatically next time. Without that loop, each finding is a one-off investigation that doesn’t compound into anything.
Diagnosing which type of hallucination you have
Fixing hallucinations effectively requires knowing which layer failed. The fix for a retrieval failure is different from the fix for a generation failure, and treating them the same way wastes time.
Retrieval hallucination happens when the retrieval system fails to surface the right document, so the LLM has no good context to draw from and generates from its own parameters instead. Signs: the answer sounds plausible but cites no sources, or the cited source doesn’t actually contain the claimed information.
Grounding hallucination happens when retrieval worked correctly but the LLM generated content that goes beyond or contradicts what was retrieved. Signs: the retrieved context is accurate, but the response adds claims not found in it.
Knowledge gap hallucination happens when the right document simply doesn’t exist in the knowledge base. The LLM fills the gap rather than saying it doesn’t know. Signs: the query is reasonable but retrieval returns low-relevance results.
A study evaluating hallucination types in RAG systems found that grounding failures (the LLM departing from retrieved context) were more common in longer-form generation tasks, while retrieval failures dominated in factoid QA (Shi et al., 2023, “Large Language Models Can Be Easily Distracted by Irrelevant Context”). Knowing which regime your application is in tells you where to focus.
Prioritizing which hallucinations to fix first
Not all hallucinations are equally worth fixing. A hallucination in a customer-facing support bot that gives wrong refund information costs more than one in an internal draft tool where humans review the output anyway. Prioritization that ignores business context leads teams to optimize for the wrong things.
Useful signals for prioritization:
- Volume: how often does this failure type appear in production?
- Severity: what is the downstream consequence when this specific hallucination reaches a user?
- User signal: are users pushing back, flagging, or abandoning when this failure type occurs?
- Fixability: is this a retrieval gap you can close by adding documents, or a fundamental generation problem that requires a different approach?
Treating every hallucination as equal and working through them in the order you found them is how teams spend months improving the wrong things.
Regression testing before rollout
When you fix a hallucination (better chunking, improved retrieval, or a tighter prompt), you need to know the fix worked and didn’t break something else. Teams that skip regression testing often introduce new hallucinations while fixing old ones.
The most reliable regression suites come from human-reviewed production examples. When a reviewer confirms a specific trace was wrong and a specific trace was right, those labeled examples become test cases. Run them against every prompt or model change before rollout. If a change that fixes one failure type causes regressions on previously working cases, you catch it before users do.
What to prioritize
If you’re just starting, the most impactful things are: clean up your knowledge base data, fix chunking if it’s producing incoherent segments, and set up basic automated monitoring so you know when output quality degrades. From there, you can invest in retrieval improvements and build out the feedback loop that drives continuous improvement.
The root cause matters. A hallucination caused by bad retrieval needs a different fix than one caused by the model misinterpreting good context. Getting that diagnosis right is what makes fixes durable rather than just patching symptoms.
A Quick Comparison of Vector Databases for RAG Systems
ApertureDB, Pinecone, Weaviate, and Milvus compared on features, performance, and RAG use cases.
 Preetam Joshi
Preetam Joshi A Practical Guide to Agentic LLM Frameworks
A practical overview of agentic LLM frameworks: reasoning, planning, tool use, and the real challenges of running them in production.
Puneet Anand LLM-as-Judge: Why It's Hard to Get Right and Why It Still Matters
When LLM-as-judge works, when it breaks down, and what it actually takes to build one you can trust.
 Puneet Anand
Puneet Anand Get started
Ready to build better AI with better data?
The real bottleneck in AI isn't intelligence. It's the data you can't generate, can't share, or can't trust.