LLM-as-Judge: Why It's Hard to Get Right and Why It Still Matters
When LLM-as-judge works, when it breaks down, and what it actually takes to build one you can trust.
DataFramer Team
LLM-as-judge has become the default approach for evaluating AI systems at scale. Running humans through every output is too slow and too expensive, so teams use another LLM to score the first one. It works well enough to get started. The trouble is that most teams don’t realize how much calibration these judges need before you can trust them, and they find out only after they’ve already built a lot on top of them.
What is LLM-as-judge?
It’s a technique where a language model evaluates the outputs of another model. You give the judge some criteria, a set of examples, and the output you want scored, and it returns a score with some explanation.

The typical setup: your base LLM handles user queries. For each output, you send the response along with the original query and any retrieved context to a separate judge LLM. The judge evaluates whether the response met your criteria, hallucinated any facts, followed the instructions, and so on. Teams use judges both inline (real-time evaluation) and in batch (offline evaluation over historical traces).
Where judges actually work
Judges are good at getting you off the ground quickly. If you have no evaluation process at all, adding an LLM judge gives you coverage fast. They’re useful for:
- Catching obvious failures like off-topic responses, formatting violations, or complete non-answers
- Comparing two versions of a prompt or model across a test set
- Running broad quality checks across thousands of traces that would take weeks to review manually
- Flagging outputs for human review rather than making final determinations
That last point matters: judges work best when they’re part of a larger process, not the final word.
Here’s how to set one up for a simple use case like evaluating student writing:
- Pick your judge model. GPT-4o for complex criteria, a smaller model if you’re evaluating at high volume and cost matters.
- Define evaluation criteria. Factual accuracy, topic adherence, style requirements, whatever matters for your use case.
- Write the evaluation prompt. Be specific about the rubric you want applied.

- Automate at scale. Submit outputs inline or in batches and collect scores automatically.
- Review results on a cadence. Don’t just trust the scores. Someone needs to audit whether the judge is getting things right.
Why getting a reliable judge is hard
Here’s the core problem: LLMs are trained to generate text, not to score it consistently. Scoring requires applying a fixed rubric the same way every time. LLMs don’t do that.
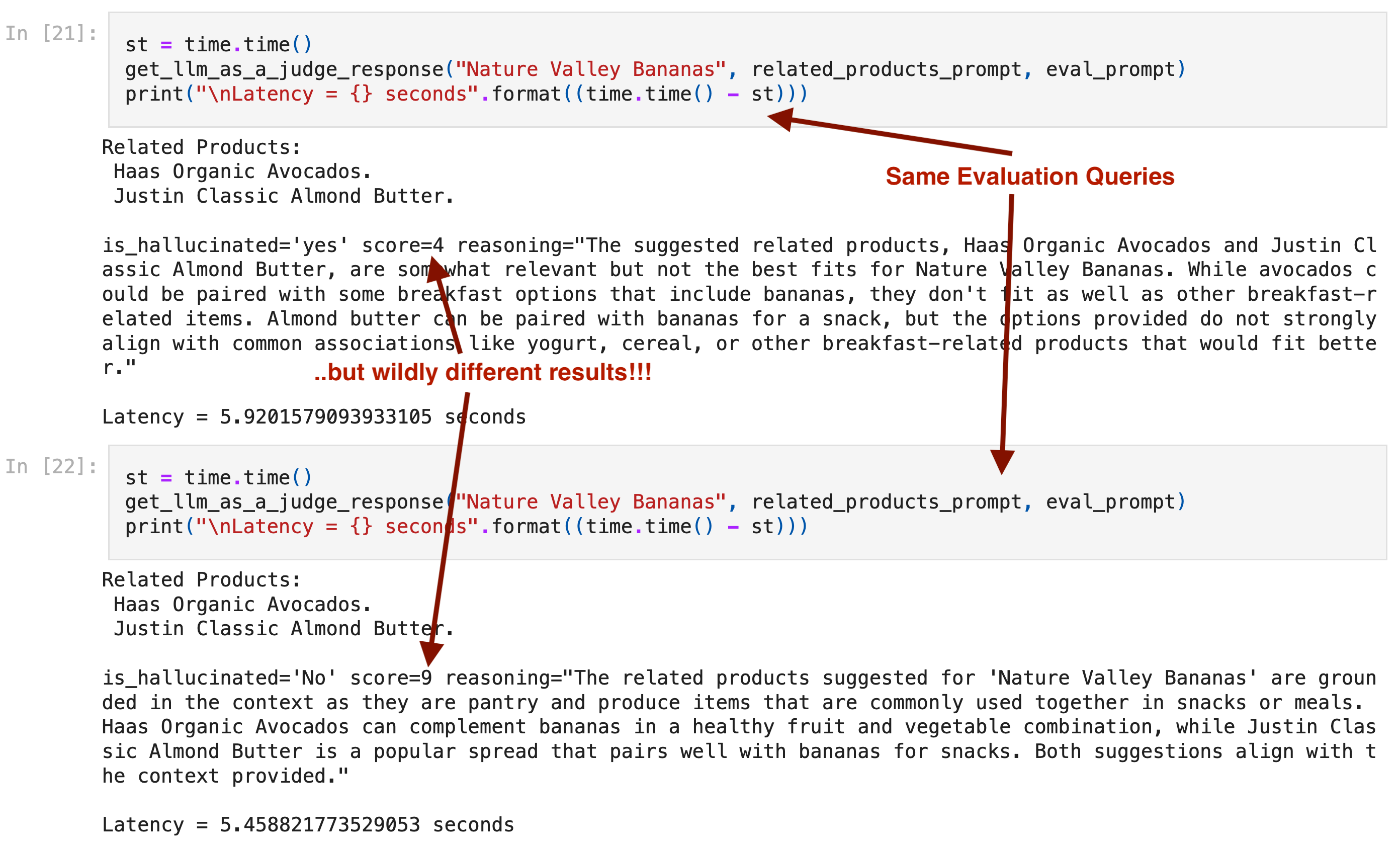
That image shows GPT-4o-mini giving different scores for the exact same query on separate runs. This isn’t a quirk. Research has documented the problem clearly:
LLMs fail to respect scoring scales given to them
— Large Language Models are Inconsistent and Biased Evaluators (link)
We find limited evidence that 11 state-of-the-art LLMs are ready to replace expert or non-expert human judges, and caution against using LLMs for this purpose.
— LLMs instead of Human Judges? A Large Scale Empirical Study (link)
The important word in that second finding is replace. An uncalibrated judge dropped in to substitute for human review is unreliable. That’s a different thing from a judge that has been calibrated against human-labeled examples and used to extend the reach of expert review rather than replace it. The rest of this article is about getting to that second case, because a well-calibrated judge is the only practical way to evaluate AI quality at production scale.
Beyond inconsistency, judges run into several other reliability problems:
Shared biases with the model they’re judging. If your primary LLM and your judge are both GPT-4o, the judge will likely miss errors that GPT-4o systematically makes. They share blind spots. Using a judge from a different model family helps.
Prompt sensitivity. Small changes to the judge prompt shift scores. Writing good evaluation criteria is harder than it looks, and fragile prompts produce fragile scores.
Cost and latency. Using a strong model as a judge means paying for inference twice: once for the output, once for the evaluation. For real-time applications this often isn’t practical.
Score drift when you switch judges. If you change your judge model (from GPT-4 to Claude, say), your historical scores may no longer be comparable. Teams tracking quality trends suddenly have a discontinuity.
The judge still needs human oversight. The stated goal was to reduce how much humans review. In practice, someone still needs to audit judge outputs regularly to verify it’s scoring correctly. Blindly trusting a judge produces false confidence.
Best practices for building judges that work
Calibrate against human feedback. The most reliable judges have been tuned to match what your human reviewers say is good or bad. Collect examples that domain experts have labeled, test whether the judge agrees, identify where it diverges, and refine the prompt or fine-tune accordingly. Research shows even few-shot examples improve consistency significantly:
Few-shot in-context learning does lead to more consistent LLM-based evaluators
— Assessment and Mitigation of Inconsistencies in LLM-based Evaluations (link)
Don’t use the same model to generate and judge. A model that produced a response is a biased evaluator of that response. Use a different model family as your judge. This paper documents the cognitive biases this introduces in detail.
Provide labeled examples of good and bad outputs. Judges given concrete examples outperform those given only abstract criteria. If your judge has seen twenty examples of what counts as a hallucination in your domain, it catches them more reliably than if you just tell it to “check for factual accuracy.”
Use chain-of-thought prompting. Asking the judge to reason step-by-step before scoring leads to more accurate and consistent evaluations. The reasoning trace also makes it easier to catch when the judge went wrong.
Build a regression suite from your human-reviewed examples. Once you’ve had humans verify a set of scores, use those as tests. When you update your judge prompt or switch models, run the regression suite to detect drift before it affects your production evaluations.
Specific failure modes to watch for
Beyond general inconsistency, judges have documented systematic biases that are worth knowing before you deploy one.
Position bias. Judges tend to favor responses that appear earlier when comparing two outputs side by side. Research from Stanford found that simply swapping the order of two responses being compared could flip a judge’s preference (Zheng et al., 2023, “Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena”). If you’re using a judge to compare prompt variations, run the comparison both ways and average the results.
Verbosity bias. Judges tend to rate longer, more detailed responses higher regardless of accuracy. A response that confidently elaborates on wrong information can score better than a shorter, correct one. This matters in RAG applications where the LLM might fill gaps with plausible-sounding elaboration.
Self-preference. When a model judges its own outputs, it tends to rate them higher than outputs from other models. Using the same model as both generator and judge compounds this. Panickssery et al. (2024) documented self-preference systematically across multiple model families.
Knowing these biases helps you design around them: run comparisons in both orderings, test whether verbose answers are genuinely better or just superficially preferred, and use a different model family as your judge.
Multi-dimensional judging vs. single scores
A single “good or bad” score hides too much. A response can be factually accurate but fail on instruction following. It can follow instructions but be irrelevant to the actual query. A judge that collapses everything into one score makes it hard to know what’s actually broken.
Breaking evaluation into separate dimensions (factual accuracy, relevance, instruction adherence, completeness) gives you specific signal you can act on. It also makes judge calibration more tractable: it’s easier to show a judge twenty examples of instruction-following violations and teach it to catch those specifically, than to teach it a single holistic quality judgment.
This is especially true for agentic systems, where different steps in a trajectory might fail on different dimensions. A scoring rubric that covers each quality dimension separately gives reviewers a structured framework and makes it possible to track which dimension is degrading over time.
The calibration loop matters more than the judge itself
The teams that build reliable judges are the ones that treat calibration as an ongoing process, not a one-time setup. They collect human-reviewed examples, test the judge against them, identify systematic errors, improve the rubric or prompt, and repeat.
That loop requires somewhere to store the reviewed examples, track reviewer agreement, and surface where the judge diverges from humans. Without that infrastructure, calibration tends to happen once and then get forgotten, and the judge drifts silently over time.
Human review is also still essential for high-stakes decisions. LLM judges are useful at scale but don’t understand your compliance requirements, your domain nuances, or what “correct” actually means for your specific business context. The best use of a judge is to extend the reach of human review, not to eliminate it.
A Quick Comparison of Vector Databases for RAG Systems
ApertureDB, Pinecone, Weaviate, and Milvus compared on features, performance, and RAG use cases.
 Preetam Joshi
Preetam Joshi A Practical Guide to Agentic LLM Frameworks
A practical overview of agentic LLM frameworks: reasoning, planning, tool use, and the real challenges of running them in production.
Puneet Anand How to Fix Hallucinations in RAG LLM Apps
Concrete techniques for diagnosing and reducing hallucinations in RAG-based LLM applications.
Puneet Anand Get started
Ready to build better AI with better data?
The real bottleneck in AI isn't intelligence. It's the data you can't generate, can't share, or can't trust.