Benchmarking Coding Agents as Math Auditors: A Synthetic Financial Document Dataset
We built a financial benchmark with planted errors to test Claude Code as a math auditor — no manual labeling needed.

Alex Lyzhov
Thu Mar 19
Summary
We wanted to show that DataFramer can construct useful evaluation datasets — including ground truth labels — with minimal human involvement, even for tasks so challenging that frontier models become unreliable.
This post is one such experiment. We built a benchmark of 20 synthetic financial PDFs (P&L statements, income statements) and used it to evaluate Claude Code (powered by Claude Opus 4.6) as a judge of mathematical consistency. The result: by default, Claude Code is not a reliable auditor — but with targeted prompting, its accuracy improves substantially.
Key results:
| # | Prompt | Precision | Recall | F1 |
|---|---|---|---|---|
| 1 | ”Check math in the documents” | 1.000 | 0.417 | 0.588 |
| 2 | ”Check math in all the documents” | 1.000 | 0.583 | 0.737 |
| 3 | ”Check mathematical consistency in all the documents” | 1.000 | 0.667 | 0.800 |
| 4 | ”…Use one subagent per document” | 1.000 | 0.667 | 0.800 |
| 5 | ”…very thoroughly…find all errors whatever it takes. Use an Opus subagent for each document” | 0.800 | 1.000 | 0.889 |
The dataset is published on HuggingFace: dataframer/math-judging.
Generating the Dataset
We started with 3 seed financial documents (P&L and income statements) and ran a straightforward workflow in DataFramer to expand them into 20 diverse PDFs. The platform’s specification system ensured diversity along two axes:
- Content diversity: different company types, table structures, line items, revenue scales, and financial periods.
- Visual diversity: distinct formatting styles, layouts, fonts, and table designs across documents — each PDF looks different.
Planted Errors with Ground Truth
We introduced a key generation property: document correctness status. In 70% of cases, the generator was instructed to insert a single, subtle consistency violation into an otherwise correct document. This might be one wrong sum out of several hundred implicit equations — a percentage that doesn’t match its components, a variance column that’s off by a small amount, a subtotal that doesn’t add up.
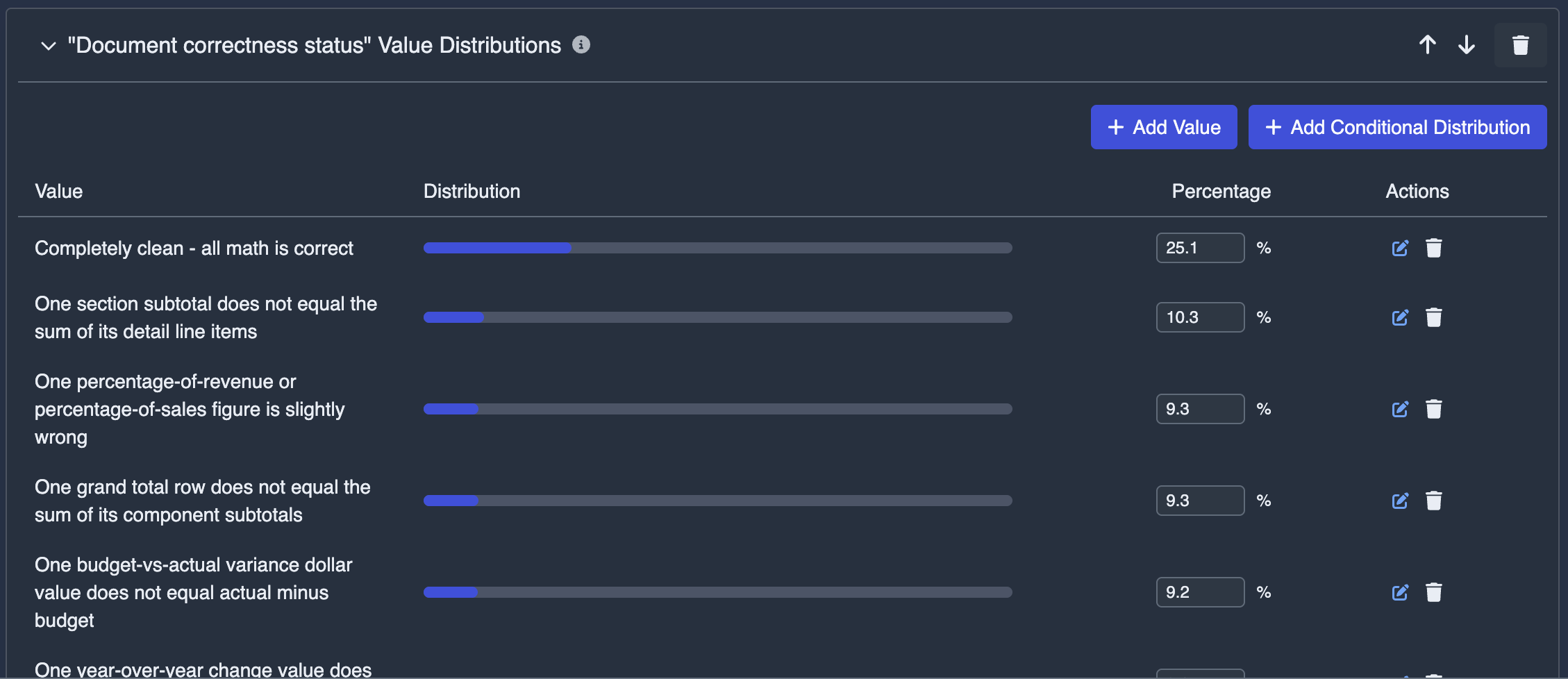
The critical design choice: we generated the ground truth labels first, then generated each document conditional on its label. This direction — label → document rather than document → label — is significantly more reliable for ensuring correctness of the ground truth.
On top of that, DataFramer’s agentic generation loop brings multiple layers of quality control:
- Tool use during generation: the calculator tool gives the LLM access to a sandboxed Python environment for verifying every numerical relationship.
- Revision cycles: conformance revisions catch internal inconsistencies that slip through initial generation.
- Filtering: conformance filters reject and regenerate documents with structural issues.
- Multi-agent pipeline: separate roles for outlining, generation, and multiple types of revision (coherence, consistency, conformance) — each stage cross-checks the output of the previous one.
The result: ground truth labels are correct 95%+ of the time — more than enough to get a reliable relative ranking of different prompts, methods, or models.
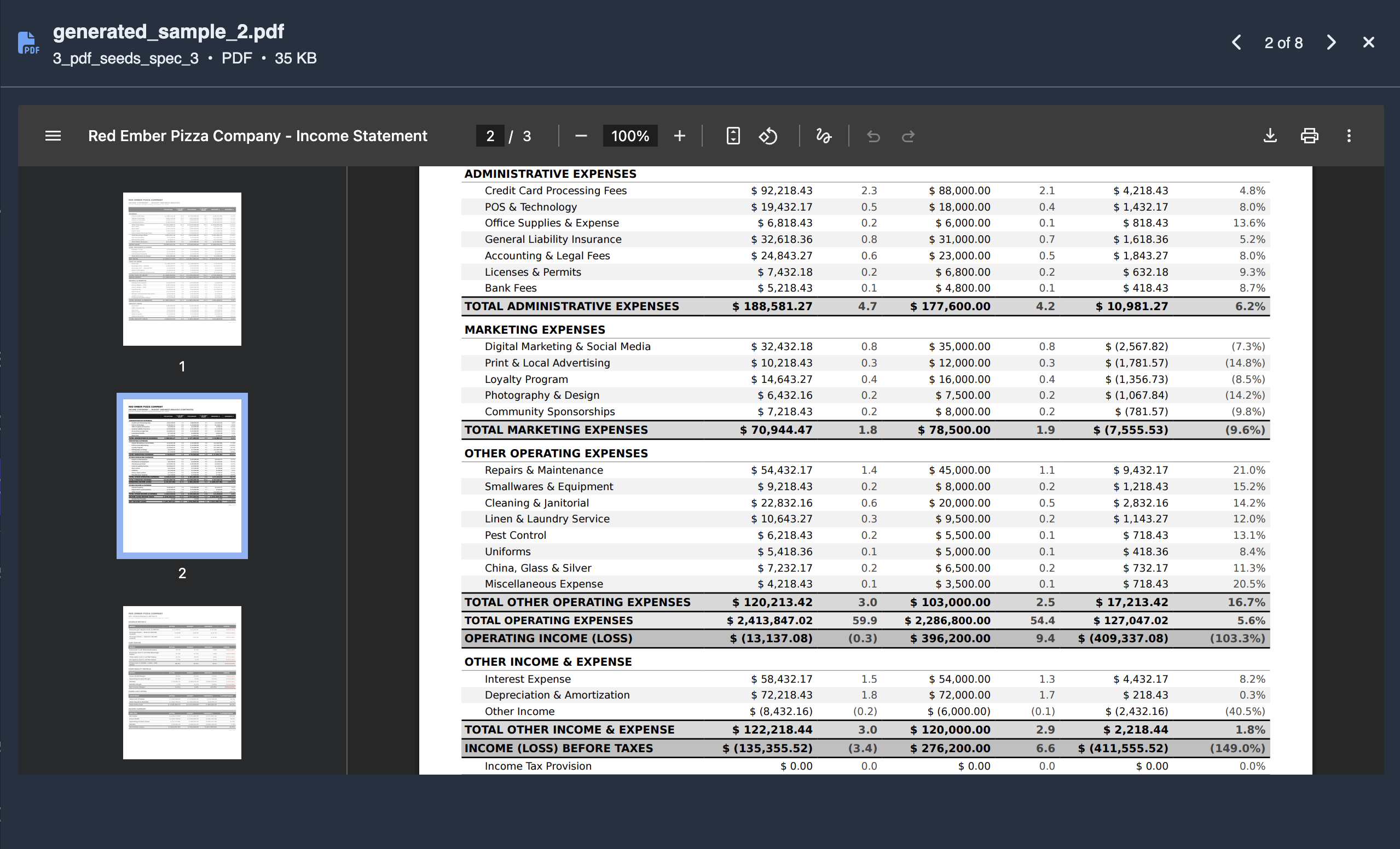
PDF Rendering
The platform also automatically renders the final documents as PDFs rather than serving raw text. This makes the task slightly more realistic — and harder — for coding agent judges like Claude Code, which must parse the PDF before they can even begin checking the math.
Evaluating Claude Code
With the dataset in hand, we used it as a laziness benchmark for Claude Code — the state-of-the-art coding agent, powered by Claude Opus 4.6, currently the most capable model available.
The task is conceptually straightforward: given a financial PDF, check whether all internal numerical relationships are consistent. A sufficiently thorough agent could verify every equation. But in practice, frontier models tend to cut corners — they spot-check a few numbers, declare everything fine, and move on. This makes them unreliable auditors by default.
We tested five prompts, ranging from minimal to exhaustive:
| # | Prompt | Precision | Recall | F1 |
|---|---|---|---|---|
| 1 | ”Check math in the documents” | 1.000 | 0.417 | 0.588 |
| 2 | ”Check math in all the documents” | 1.000 | 0.583 | 0.737 |
| 3 | ”Check mathematical consistency in all the documents” | 1.000 | 0.667 | 0.800 |
| 4 | ”…Use one subagent per document” | 1.000 | 0.667 | 0.800 |
| 5 | ”…very thoroughly…find all errors whatever it takes. Use an Opus subagent for each document” | 0.800 | 1.000 | 0.889 |
Precision tends to be high — when Claude Code flags an error, it’s usually real — though it drops when the model is pushed to be exhaustive (prompt 5 introduces a few false positives). The bigger issue is recall: with minimal prompts, a significant fraction of planted errors go undetected. Only when we explicitly instructed the agent to be exhaustive, to check every mathematical relationship, and to delegate each document to a dedicated Opus subagent (which is not the default behavior) did recall approach 100%.
What’s Actually Happening
The behavior differences are revealing:
- Prompt 1: Read 10 of 20 PDFs sequentially, then stopped. Never touched the other half.
- Prompt 2: Read all 20 PDFs but checked everything solo.
- Prompt 3: Read all 20 PDFs itself, then launched 8 subagents in batches.
- Prompt 4: Launched 20 subagents (one per document) without reading the PDFs itself.
- Prompt 5: Launched 20 Opus subagents (one per document), each instructed to be exhaustive.
The pattern is clear: out of the box, Claude Code is not a reliable judge for this task. It takes shortcuts — reading only some documents, skipping checks, not delegating work. Only with explicit instructions to be thorough and use capable subagents does accuracy reach acceptable levels.
The Workflow
The end-to-end process required minimal manual effort:
- Seed: 3 example financial documents.
- Spec: DataFramer analyzed the seeds and generated a specification with content and style distributions, plus our custom correctness property.
- Generate: 20 diverse PDFs produced with calculator tool, conformance revisions, and PDF rendering enabled.
- Verify (optional): We ran semi-automated checks on the generated labels and found 95%+ correctness. This step isn’t strictly necessary — even with a couple of mislabeled documents, the dataset is still good for comparing prompt strategies since we care about relative performance.
 5. Evaluate: Claude Code evaluated each PDF under multiple prompt variants. Results compared against ground truth labels.
5. Evaluate: Claude Code evaluated each PDF under multiple prompt variants. Results compared against ground truth labels.
The whole dataset — documents and labels — came out of the platform without much manual effort.
Try It Yourself
Reproduce the full generation workflow: ![]()
The dataset is available on HuggingFace: dataframer/math-judging
You can swap in your own agent or model, adjust the prompts, or use this as a template for building evaluation datasets for entirely different tasks. The same approach works for other tasks and other agents — even when the task is hard enough that frontier models aren’t reliable out of the box.
Want to build a dataset like this for your own use case? Try DataFramer — you can go from a few seed documents to a full evaluation set in minutes.
Synthetic Text-to-SQL Data Generation with 100% SQL Validity Using Claude Haiku
How we generated 500 diverse, 100% valid text-to-SQL samples for LLM evaluation and fine-tuning using only Claude Haiku.
Alex Lyzhov Building a Cyber Insurance Evaluation Dataset in 3 Easy Steps with DataFramer.
Scale a few real cyber insurance samples into a full evaluation and training dataset in three steps.
 Puneet Anand
Puneet Anand Synthesizing Fraud Transaction Scenarios Before Production
Generate labeled fraud scenarios on demand so you can train and benchmark before attacks reach production.
 Gabriel Marrocos
Gabriel Marrocos Get started
Ready to build better AI with better data?
The real bottleneck in AI isn't intelligence. It's the data you can't generate, can't share, or can't trust.